SQL-02100
Application team is approaching and reporting: “We do receive the following error on production!”:
SQL-02100: Out of memory (i.e., could not allocate) SELECT * FROM dual;This is a clear indicating for running out of PGA memory.
Well, this is suspicious! This is a lightweight application, using an AWS Oracle RDS instance with 24G SGA and 32G memory. Just a few sessions are connected and the workload is quite low. Increasing memory doesn’t appear to be a feasible option.
Something is wrong here!
Investigate PGA
Total PGA usage over time
To review the PGA consumption, and get an impression over the last hours/days, I went through historic statistics:
set pagesize 0
SELECT /*ansiconsole*/
snap_id,
name,
round(
(value / 1024 / 1024), 2
) mb
FROM
sys.dba_hist_pgastat
WHERE
name IN ( 'maximum PGA allocated', 'total PGA allocated', 'total PGA inuse' )
ORDER BY
snap_id DESC;
snap_id name MByte
------- -------- --------
39160 maximum PGA allocated 15632,74
39160 total PGA allocated 13963,92
39159 total PGA inuse 13208,2
39159 maximum PGA allocated 15632,74
39159 total PGA allocated 13969,24
39158 total PGA inuse 13212,63
39158 maximum PGA allocated 15632,74
39158 total PGA allocated 13971,3
39157 total PGA inuse 13393,51
...
Just for clarity, 8GB from 32GB RAM for OS and PGA is available. We do have a situation here! Around 15GB PGA is to much.
Identify high consumer process
SELECT /*ansiconsole*/
spid,
program,
round(
(pga_max_mem / 1024 / 1024), 2
) max,
round(
(pga_alloc_mem / 1024 / 1024), 2
) alloc,
round(
(pga_used_mem / 1024 / 1024), 2
) used,
round(
(pga_freeable_mem / 1024 / 1024), 2
) free
FROM
v$process
ORDER BY
alloc DESC
FETCH FIRST 10 ROWS ONLY;
SPID PROGRAM MAX ALLOC USED FREE
31069 oracle@ip-172-x-x-xxx (Q007) 2122,21 2122,21 2121,76 0,19
31077 oracle@ip-172-x-x-xxx (Q00B) 2042,33 2042,33 2041,69 0,5
31075 oracle@ip-172-x-x-xxx (Q00A) 2026,71 2026,71 2025,76 0,81
31073 oracle@ip-172-x-x-xxx (Q009) 998,71 998,71 997,76 0,75
31071 oracle@ip-172-x-x-xxx (Q008) 754,64 754,64 753,78 0,63
30902 oracle@ip-172-x-x-xxx (MMON) 124,03 106,22 6,37 1,25
30908 oracle@ip-172-x-x-xxx (S000) 107,62 100 2,66 95,94
18749 oracle@ip-172-x-x-xxx (S001) 98,75 98,5 2,42 94,94
1228 oracle@ip-172-x-x-xxx (M005) 73,89 73,89 31,5 41,13
29041 oracle@ip-172-x-x-xxx (J000) 72,14 72,14 2,37 68,94
It looks like there is a huge consumption from the EMON processes.
Let’s validate:
SELECT /*ansiconsole*/
program,
action
FROM
v$session
WHERE
process IN ( '31069', '31077', '31075', '31073', '31071' );
PROGRAM ACTION
----------------------------- -------------------
oracle@ip-172-XX-X-XXX (Q009) EMON Regular Slave
oracle@ip-172-XX-X-XXX (Q00A) EMON Regular Slave
oracle@ip-172-XX-X-XXX (Q007) EMON Regular Slave
oracle@ip-172-XX-X-XXX (Q00B) EMON Reliable Slave
oracle@ip-172-XX-X-XXX (Q008) EMON Regular Slave
Release the occupied memory
Discussed the findings with the application team. They assured that they don’t make use of Advanced Queuing – AQ and finally the EMON process. In consequence, there is no good reason why the process is consuming so much memory.
Kill EMON session
To free up the memory, as a quick hack, I did kill the EMON sessions. While using a managed AWS Oracle RDS database, I need to make use of the following procedure:
begin
rdsadmin.rdsadmin_util.kill(
sid => &sid,
serial => &serial_number,
method => 'IMMEDIATE');
end;
/
Validate impact
And with the following SQL, we may prove that the memory has been given back.
set pagesize 0
SELECT /*ansiconsole*/
snap_id,
name,
round(
(value / 1024 / 1024), 2
) mb
FROM
sys.dba_hist_pgastat
WHERE
name IN ( 'maximum PGA allocated', 'total PGA allocated', 'total PGA inuse' )
ORDER BY
snap_id DESC;
snap_id name MByte
------- --------------------- ---------
39181 total PGA allocated 1562,51
39181 total PGA inuse 918,59
39181 maximum PGA allocated 15632,74
39180 total PGA inuse 932,96
39180 maximum PGA allocated 15632,74
39180 total PGA allocated 1569,42
39179 total PGA inuse 904,54
39179 maximum PGA allocated 15632,74
39179 total PGA allocated 1541,98
39178 total PGA inuse 1087,88
39178 maximum PGA allocated 15632,74
39178 total PGA allocated 1859,96
39177 total PGA inuse 1006,59
39177 maximum PGA allocated 15632,74
39177 total PGA allocated 1751,93
39176 total PGA inuse 1082,49
39176 maximum PGA allocated 15632,74
39176 total PGA allocated 1839,75
39175 total PGA inuse 13612,15
39175 maximum PGA allocated 15632,74
39175 total PGA allocated 14571,06
39174 total PGA inuse 13755,79
39174 maximum PGA allocated 15632,74
39174 total PGA allocated 14771,22
39173 total PGA inuse 13604,78
39173 maximum PGA allocated 15632,74
39173 total PGA allocated 14553,55
39172 total PGA inuse 13749,94
39172 maximum PGA allocated 15632,74
39172 total PGA allocated 14760,78
39171 total PGA inuse 13520,38
39171 maximum PGA allocated 15632,74
Are we affected by a bug?
We are not done here! How could this happen? What’s the root cause for EMON process burning PGA?
During my research in the Internet, I could find the following post:
19.12 Linux – PGA MEMORY VERY LARGE DUE TO Q PROCESSES – BACKGROUND Streams EMON Regular Slave
The post is referring to Oracle Support note:
AQ PL/SQL Callbacks Are Not Invoked After Applying the 19C DB July RU (Doc ID 2807234.1)
Thanks Marcelo Marques, by the way!
The support note sounds promising! Maybe we are affected by bug 33249621.
Check database version and patch level
SELECT /*ansiconsole*/
status,
action_time,
description
FROM
dba_registry_sqlpatch
WHERE
patch_type = 'RU'
ORDER BY
action_time DESC;
status action_time description
---------------- ------------------------------ ---------------------------------------------------
SUCCESS 04.11.2021 16:50:08,841886000 Database Release Update : 19.12.0.0.210720 (32904851)
SUCCESS 27.07.2021 15:52:27,321391000 Database Release Update : 19.11.0.0.210420 (32545013)
WITH ERRORS (RU) 27.07.2021 15:51:36,792489000 Database Release Update : 19.11.0.0.210420 (32545013)
SUCCESS 09.06.2021 15:57:01,702454000 Database Release Update : 19.10.0.0.210119 (32218454)
WITH ERRORS (RU) 09.06.2021 15:56:13,395982000 Database Release Update : 19.10.0.0.210119 (32218454)
SUCCESS 16.11.2020 16:54:02,280031000 Database Release Update : 19.8.0.0.200714 (31281355)
SUCCESS 31.08.2020 15:51:44,293871000 Database Release Update : 19.7.0.0.200414 (30869156)
SUCCESS 18.02.2020 06:39:30,743061000 Database Release Update : 19.5.0.0.191015 (30125133)
We do have the same version 19.12.0.0.210720 like in the support note!
Check AQ QUEUE
SELECT /*ansiconsole*/
owner,
name,
enqueue_enabled,
dequeue_enabled
FROM
dba_queues
WHERE
name = 'AQ_SRVNTFN_TABLE_Q_1';
OWNER NAME ENQUEUE_ENABLED DEQUEUE_ENABLED
----- -------------------- --------------- ---------------
SYS AQ_SRVNTFN_TABLE_Q_1 YES NO
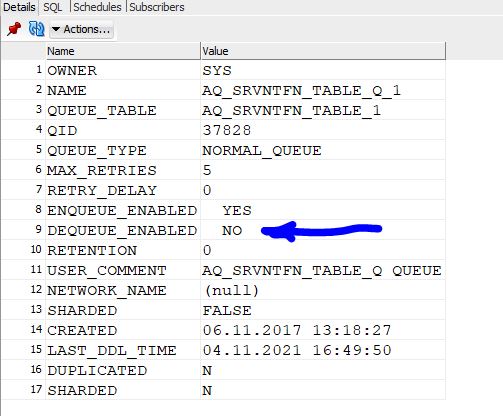
Dequeue is disabled!
There’s a perfect match with the support note. Looking around on other databases, now knowing where to look at, we do have the same situation.
Trying to implement the recommended workaround:
EXEC DBMS_AQADM.start_queue('SYS.AQ_SRVNTFN_TABLE_Q_1');
....
01031. 00000 - "insufficient privileges"
*Cause: An attempt was made to perform a database operation without
the necessary privileges.
*Action: Ask your database administrator or designated security
administrator to grant you the necessary privileges
Well, it’s a managed database service. I’m done here, because I do not have the sys privilege.
Time to open a service request. I’ll keep you posted.
Update
Well, some more database are coming up with the same issue, now. All patched with RU12 around the same time.
The following procedure appeared to be successful:
SELECT /*ansiconsole*/
owner,
name,
enqueue_enabled,
dequeue_enabled
FROM
dba_queues
WHERE
name like 'AQ_SRVNTFN_TABLE_Q_%';
OWNER NAME ENQUEUE_ENABLED DEQUEUE_ENABLED
SYS AQ_SRVNTFN_TABLE_Q_1 YES NO
SYS AQ_SRVNTFN_TABLE_Q_2 YES NO
If DEQUEUE_ENABLED is equal to NO, please enable DEQUEUE_ENABLED:
EXEC DBMS_AQADM.start_queue('SYS.AQ_SRVNTFN_TABLE_Q_1');
EXEC DBMS_AQADM.start_queue('SYS.AQ_SRVNTFN_TABLE_Q_2');
Monitor the following table to make sure the amount of rows is decreasing:
select count(*) from AQ_SRVNTFN_TABLE_1;
select count(*) from AQ_SRVNTFN_TABLE_2;
This must be done on CDB and PDB level!